This article is based on the book “Swarm Intelligence” by James Kennedy and Russel C. Eberhart.
Neural networks
Neural networks are Machine Learning algorithms that learn how to make a task using training examples. This algorithm simulates the behavior of our brains to learn patterns in data.
We have three main parts in Neural Networks: neurons, layers, and backpropagation.
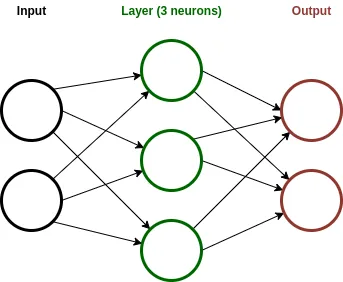
In this image, we have a neural network with one layer and 3 neurons. The neural network gets the data from the input layer and transforms the data according to the structure defined.
Each of these arrows and neurons represents an operation in the network. Usually, these operations are multiplication and sum between the data and weights.
These weights are calculated using an optimization algorithm called backpropagation. Backpropagation is a method that exploits the chain rule of calculus to obtain the best neural network weights.
In this article, we will optimize our neural network without backpropagation. Instead, we will apply a bio-inspired algorithm Particle Swarm Optimization.
Particle Swarm Optimization (PSO)
PSO is an optimization algorithm inspired by biological behavior. Unlike Backpropagation, PSO does not use gradients. It is a metaheuristic as it does not guarantee an optimal solution. However, it can search in very large spaces of candidate solutions. There are three main parts in PSO: particles, constants, and iterations.
Particles
The first element in PSO is the particle. In the beginning, we will define the number of particles to be produced. All particles will be a potential solution. As we want to optimize a neural network using PSO, each particle will have a weights combination of our network.
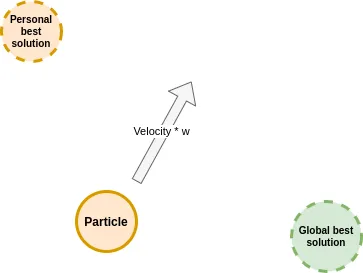
Also, each particle will have three properties, velocity (random at the beginning), the personal best solution (best solution found by the particle), and global best solution (best solution found by the swarm). These properties will determine the direction of the particle.
Constants
There are three main constants in this algorithm: cognitive coefficient (c1), social coefficient (c2), and inertia (w). Each of these constants is related to the personal best solution, the global best solution, and the velocity of the particles.
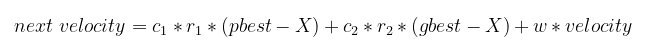
Where X is the current position, r1 and r2 are random numbers, pbest is the personal best solution, gbest is the global best solution, and velocity is the current velocity.
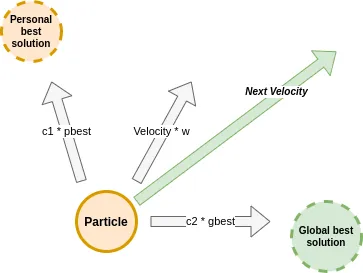
Following this rule for each particle, we will optimize the solution balancing between what a particle believes is the best solution, what the swarm believes is the best solution, and the current movement inertia.
Iterations
The iterations are the number of times that the particles will update their velocities. In each iteration, the particles will move to search for the best solution.
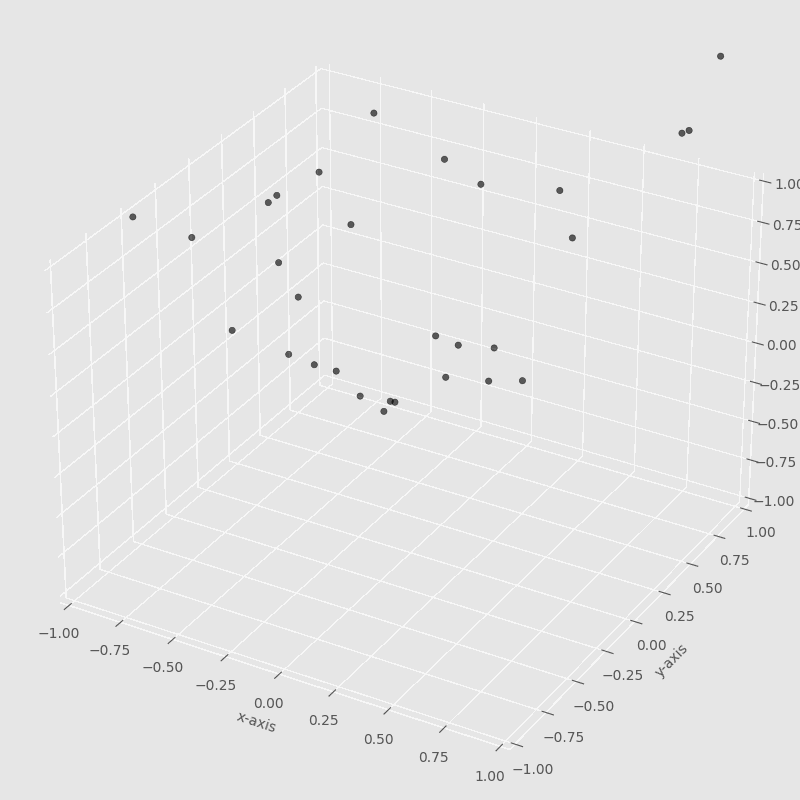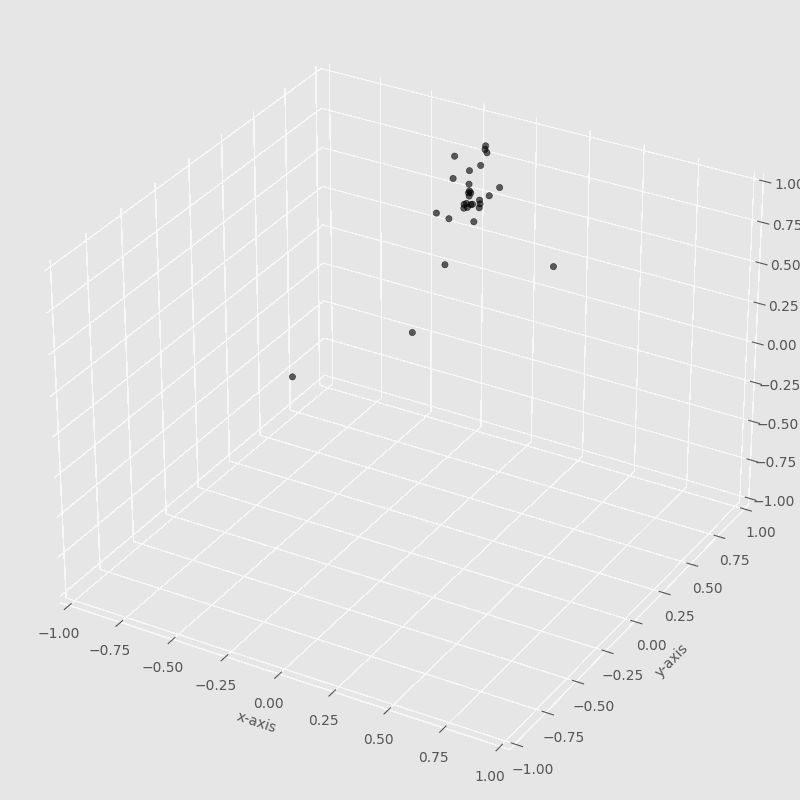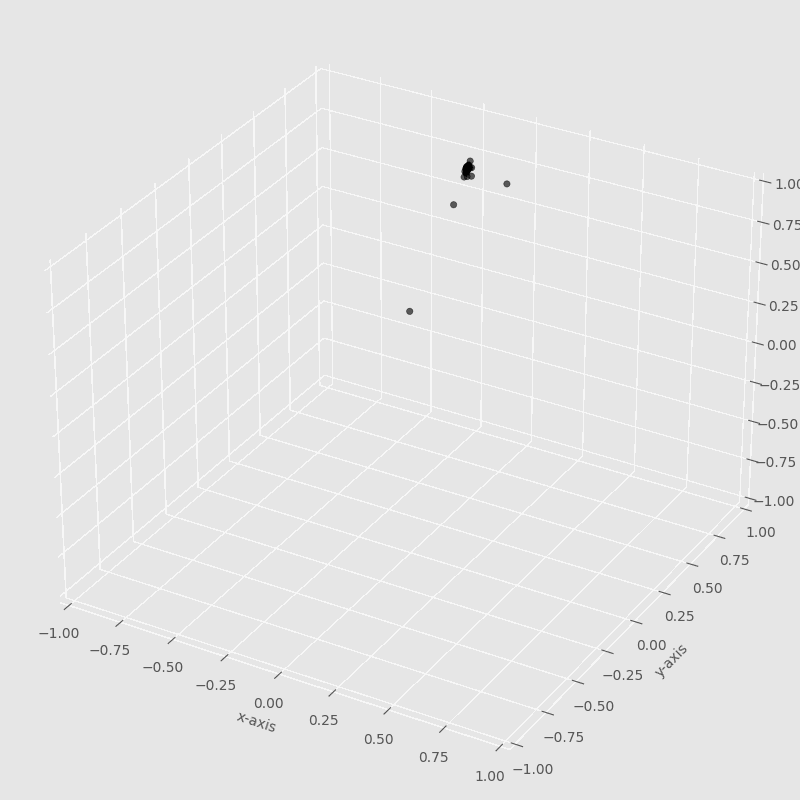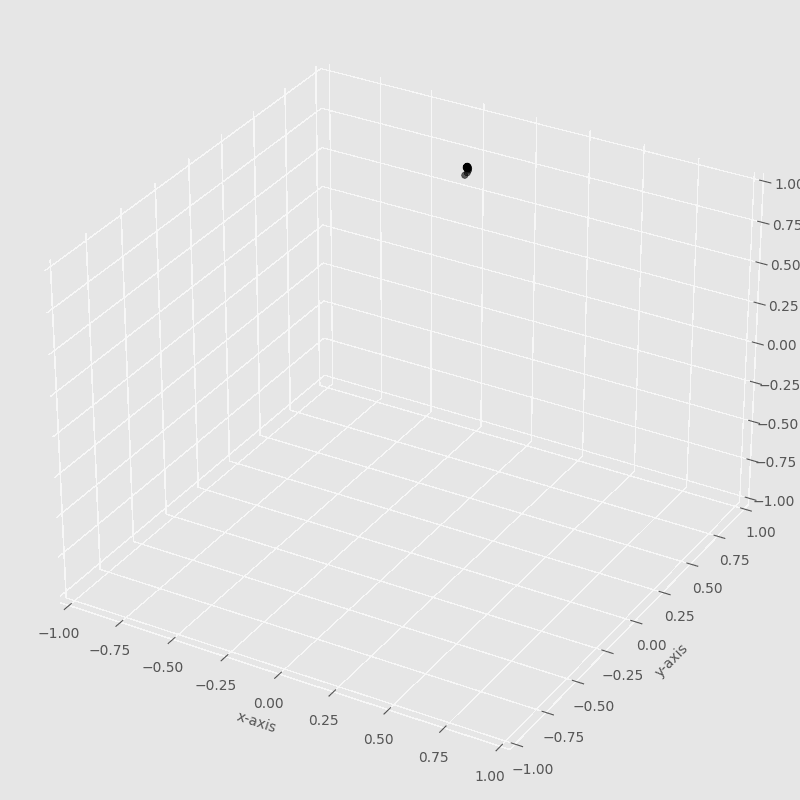
In this image, we can observe how each particle is moving around to find the best solution. The particle that found the best solution will attract all the others until others find the best solution.
Pyswarms
In this project, we are going to use the PSO optimization library pyswarms.

The library can be installed using pip:
<pip install pyswarms>
Building the neural network
First, we are going to build a test case using keras and scikitlearn. We are going to use dataset iris.
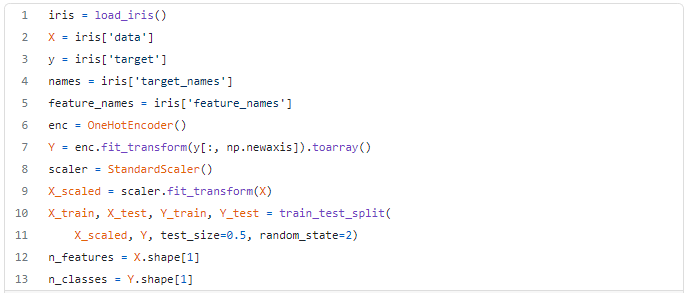
The function create_custom_model will help us to build our network.
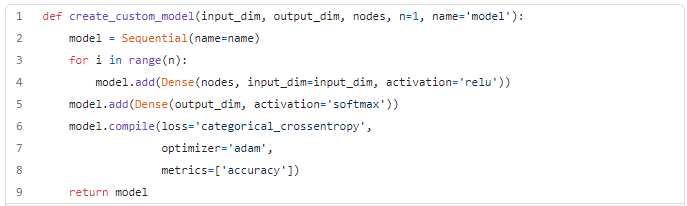
Then, we build our network structure with 4 neurons and 1 layer.
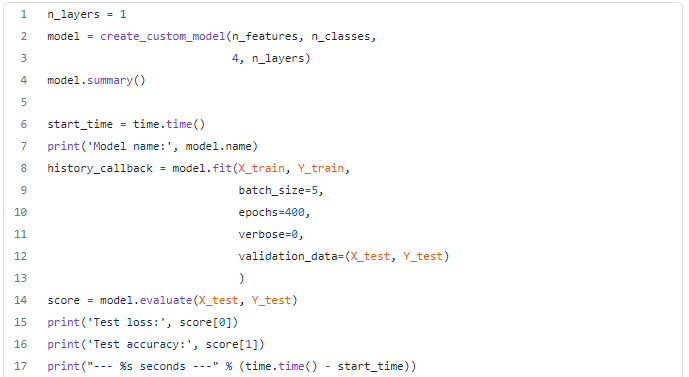
In order to use PSO, we need to extract and set the structure of the network.
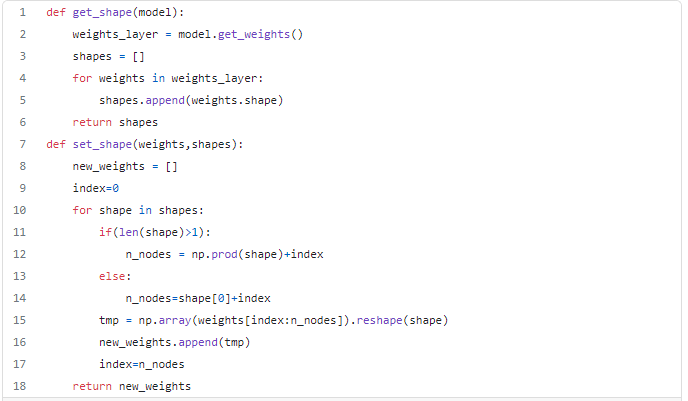
The optimization function
We need to build an optimization function.

The optimization function in pyswarms needs 1 parameter W with all the solutions of each particle. Then, we can add all the additional variables that we need. In our case, we will give the network structure shape, the training dataset, and their labels.
Finally, the function needs to return the result of each particle solution. In our case, we return the variable results that collect each accuracy from each model. Pyswarms minimize the function so we need to subtract 1 to each accuracy.
Configuration and optimization
We need to define the properties of our swarm (c1, c2, w, and boundaries).

In this example, we set the c1 to 0.4, c2 to 0.8, and w to 0.4 because this problem has low complexity. So, the exploitation will be crucial. Also, we define boundaries because each weight will be between -1.0 and 1.0.
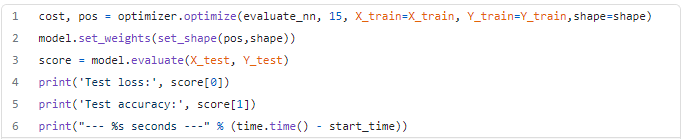
Finally, we set the number of iterations using optimize function and we use the test dataset to evaluate the result of our optimization.
Results
We use the same structure but using a cross validation of 5 folds.
MLP Backpropagation:
0.96 +/- 0.02
MLP PSO:
0.91 +/- 0.03
There are more optimization that we can apply to PSO to improve the results that we will explore in other articles like decreasing inertia, levy flight distribution, imperial modification, and combine PSO with Backpropagation.
Moreover, there are other research where the authors explore the performance of PSO in front of backpropagation like these ones:
Particle Swarm Optimization over Back Propagation Neural Network for Length of Stay Prediction
Optimizing Artificial Neural Network for Functions Approximation Using Particle Swarm Optimization
Disadvantages:
PSO could present competent results with MLP. However, there are some cases where PSO can not find a good solution. That reduces the average accuracy. Also, Backpropagation has optimization made by Tensorflow that reduces the time processing.
Advantages:
PSO does not need a differentiable function. So, PSO can be used when the gradient is not available.PSO can perform a global search in the problem space. Using PSO, we can customize the speed of learning and performance using the optimization function.